Research
We are a group of machine learning researchers working on “Multi-modal, Complex reasoning systems at Scale”.
For foundation model optimization, we continued to expand GEARBox, our suite of techniques for optimizing the compute and memory requirements of large-scale foundation models. We also developed AFLORA, a novel parameter-efficient fine-tuning method for LLMs. We do research on inference-efficiency of large models, be it Transformer-based models or recurrent models such as MAMBA. We worked on long-form video representation research using sparse transformers and graphs and produced state-of-the-art results on several benchmarks. We innovate in video-llm space for improved temporal understanding.
We do advanced research on AI for chip design. Finally, we are accelerating and democratizing AI for science - focusing on new benchmarks and tools for Material Science and Protein Synthesis.
We built one of the first foundation models for graphs and geometric deep learning: graph node classification, knowledge graph reasoning; we devise the fastest billion-scale graph learning platforms.
Here are some themes and techniques that we currently work on:
Gen AI for Video.
Multimodal-LLMs.
We have developed a training-free flexible pipeline, VideoNarrator, for video search and summarization utilizing multimodal LLMs (MLLMs) and vision-language models (VLMs) in a modular fashion by providing functionalities of caption generation, context provider & caption refiner and caption verifier. Our solution chieved 4–9% accuracy improvements across top-performing MLLMs including Phi-4, InternVL, Qwen, Molmo, miniCPM, and VideoLLaVA. The core technology deployed in Intel’s open-source tool: video-search-and-summarization . We are advancing the capabilities of video-LLMs with parameter-efficient finetuning (PEFT). We’ve developed GO-Tokenizer, an object-level tokenization method for encoding compact object level information on-the-fly in a plug-and-play fashion to improve temporal comprehension capability of existing video-LLMs. In a recent work, we have designing reference-free evaluation metrics for video captioning with factual analysis — fully local and independent of cloud-based LLM APIs.
Refer to the Medium blog that can take you to a 7-minutes read summarizing the 12-years journey that will take you from image-classification to video-LLMs!
Video and Multimodal Generation.
We are driving algorithmic advancements to enhance the capabilities of World Models (e.g., COSMOS) and diffusion-based video generation models (e.g., Wan, HunyuanVideo, LTX Video, VACE) for zero-day deployment. We are currently working towards novel control mechanisms for user-friendly video generation and editing framework and we are focusing on novel evaluation metrics for motion consistency for video generation models.
Long-Form Video Representation Learning.
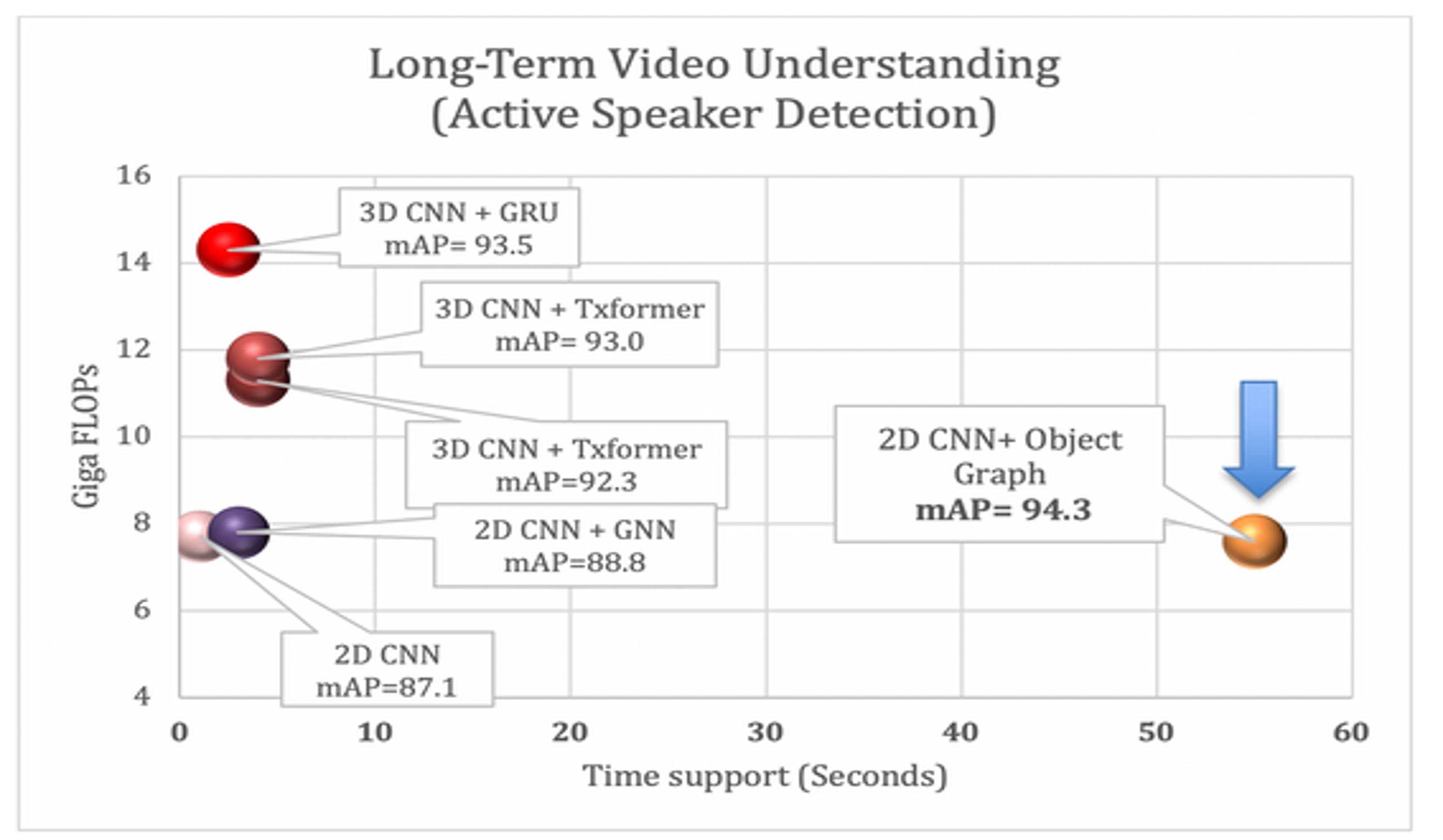
We push the boundaries of long-form video representation learning, devising architectural motifs which leads to context aggregation over 10X-50X longer time support compared to existing methods. We take the approach of sparse models, either by explicitly modeling videos as a spatio-temporal graph or by learning sparse video-text transformers. Our method achieves state-of-the-art results at a fraction of the memory and compute cost of dense transformers. On a wide range of settings, the longer temporal support enabled by the novel representations consistently increases accuracy. They outperform on several downstream applications and benchmarks including but not limited to video recognition, video question-answering, episodic memory tasks, active speaker detection, action detection, temporal segmentation, multimodal retrieval, keystep recognition, and video summarization.
Refer to the 3-series TDS blog to know more about this project. With a focus on open research, we established Intel Labs as a thoughtleader for video and multimodal foundation models; we published heavily on prestigious AI venues; be at top-positions on leadersboards targeting several different video understanding applications. 30+ publications at CVPR, ICCV, ECCV, NeurIPS, ICLR in the last 4 years!
We do research on making Video-llms more accurate on temporal understanding tasks. We do so by harnessing grounded-object information into several SOTA Video-LLM models and show how the performance on several temporal understandings improve with minimal finetuning. We developed a training-free dense video-caption generator, VideoNarrator, which powers several internal and external usecases. We have developed a quality evaluation framework for video captioning evaluating several metrics including “reference-free” methods as well. Many exciting algorithms are being developed right now! We are looking forward to share those works with the world soon!
Foundation Model Optimization (FoMo).
The foundation model optimization research of AIL focuses on model architecture develpment, efficient fine-tuning, latency and/or throughput efficient inference methodologies. The borader goal is to support million scale tokens at limited compute and memory budget. In the model architecture development space, our research primarily focuses on sub-quadratic attention mechanisms. Towards that goal, our work SAL-ViT (ICCV 2023) presents an hybrid architecture having quadratic attention and sub-quadratic attentions at different layers based on their operational performance sensitivity. Refer to the paper.
-
Secondly, we have dedicated research efforts ongoing to advance the foundation model fine-tuning research for their efficient trainability on downstream task with limited data and resources (CVPR 2024, ICLR 2024). A recent work from our lab that maintains the current SoTA in PEFT is here.
-
Lastly, to advance the LLM inference efficiency, we have recently collaborated on a multi-institution project, namely project GEAR (generative inference via approximation and error recovery). To know more about the project please refer to the project page.
-
Other research in this thread includes data-free quantization for privacy preserving fine-tuning, foundation model applications in RTL design, robsutness vulnerability of efficient model deplyment.
Graph Foundation Models.
Foundation Models in language, vision, and audio have been among the primary research topics in Machine Learning in 2024 whereas FMs for graph-structured data have somewhat lagged behind. We argue that the era of Graph FMs has already begun and developing algorithms and novel primitives for graph foundation models.
For years, GNN-based node classifiers have been limited to a single graph dataset. We have developed GraphAny is, the first Graph FM where a single pre-trained model can perform node classification on any graph with any feature dimension and any number of classes. A single GraphAny model pre-trained on 120 nodes of the standard Wisconsin dataset successfully generalizes to 30+ other graphs of different sizes and features and, on average, outperforms GCN and GAT graph neural network architectures trained from scratch on each of those graphs. Please refer to this TDS blog to know more about GraphAny.
We developed ULTRA, a foundation model for knowledge graph (KG) reasoning. A single pre-trained ULTRA model performs link prediction tasks on any multi-relational graph with any entity / relation vocabulary. Performance-wise averaged on 50+ KGs, a single pre-trained ULTRA model is better in the 0-shot inference mode than many SOTA models trained specifically on each graph. Following the pretrain-finetune paradigm of foundation models, you can run a pre-trained ULTRA checkpoint immediately in the zero-shot manner on any graph as well as use more fine-tuning. ULTRA provides unified, learnable, transferable representations for any KG. Under the hood, ULTRA employs graph neural networks and modified versions of NBFNet. ULTRA does not learn any entity and relation embeddings specific to a downstream graph but instead obtains relative relation representations based on interactions between relations. Refer to the website to learn more on our graph foundation model.
Democratizing machine learning on billion-scale graphs is a core focus of Intel AI Lab. Our goal has been to shift this important AI training workload from expensive GPUs to inexpensive CPUs. Our SAR framework already allows a seamless transition from training on a single machine to fully distributed training with linear peak-memory scaling guarantees - this set the fastest reported training times on CPUs for billion scale graph learning.
AI for Science.
We have been leading a variety of research efforts on AI for Science at Intel Labs along with external collaboration spanning various research institutions, including:
- Matter Lab led by Alán Aspuru-Guzik at the University of Toronto Overview.
- MILA, including multiple academic PIs Overview.
- Intel + Merck Group Research Center on AI for Sustainable Semiconductor Manufacturing. Overview.
- We organized the 1st AI for Accelerated Materials Design (AI4Mat) Workshop at NeurIPS 2022, followed by the next one at NeurIPS 2023. Overview.
AI for Chip Design.
Learning mechanisms for Electronic Design Automation (EDA) are increasingly becoming a focal point in research. These mechanisms hold the promise of delivering performance gains and quality improvements by orders of magnitude. Currently, our work is centered on the floor planning problem. We have developed solutions that outperform classical search solutions in both speed and quality. We extended our “human-quality floorplanner” to handle irregularly shaped rectilinear partitions instead of only rectangles. We also published FloorSet, the first ever large-scale open benchmark comprising more than 2M synthetic floorplan layouts that mimic the statistical distribution of real SOC floorplans and a range of real-world design constraints.

