Edit2Motion
Edit2Motion Overview:
We present a training-free approach for image-to-video generation that enables object-level motion control under a stable camera. Unlike prior approaches that rely on learned trajectory, bounding box, mask, or motion field guidance, our framework leverages target-frame-based motion control with an existing first-frame-last-frame video generator for accurately following desired object movements while maintaining scene stability without additional model fine-tuning. To ensure a consistent and possible target frame, we first compare and select the best single-frame background inpainting method. Then, we further introduce semantic-guided object insertion. Preliminary results show that background inpainting quality and reasonable object placement location in the target key frame critically impact motion plausibility and overall visual quality. Leveraging these insights, we develop (1) a training-free pipeline to assist users with better object-level motion generation with stable cameras, and (2) a novel automated pipeline for generating benchmark pairs of first and last frames in stable-camera scenarios. Our Edit2Motion pipeline demonstrates consistent motion controllability without training, making it a practical tool for object-level motion control with stable camera scenarios.
Edit2Motion: Training-Free Pipeline and User Interface

The Edit2Motion Pipeline is constructed with three components, where the user can interact with the application at stage 1 (Background Inpainting) and stage 2 (Object Placement). Then the original input image and the user-edited last frame are sent to a first-frame last-frame (FFLF) video generator to acquire the final video generated based on the given input image and user preference
Semantic Guided Object Placement
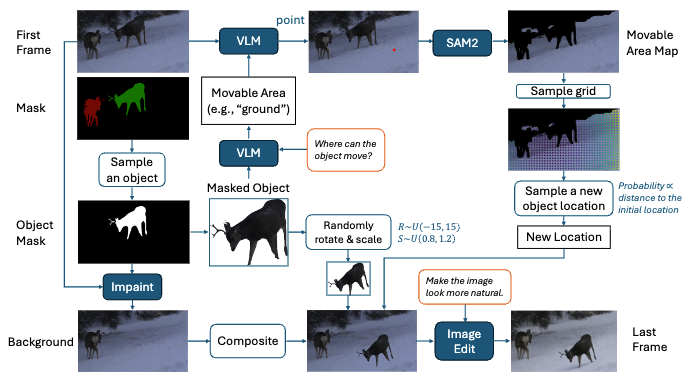
Semantic-guided object placement pipeline consists of detecting plaussible placement regions, guiding the user and finally applying a SOTA image editing tool to refine object integration.
Demo 1:
The following screen capture shows the steps: user starts with the first frame, then just a click on the chitah to automatically get the segmented chitah and an impainted background. Next the user automatically receives a visually grounded signal about where the Chitah can move. Once the user places the Chitah anywhere in the suggested area, the last frame of the video gets created. Next, the first-frame last-frame guided video generation happens in the final step. For the sake of easier visualization, we have captured everything running in real-time except for object insertion and video generation which takes about 2 minutes to complete.
Demo 2:
Next demo shows a bird flying animation generated using the pipeline. Note how the object motion is rendered realistic while the background changes from plain sky to the birdeye view of the scene below.
Demo 3:
The last demo shows a dynamic scene under the sea.

