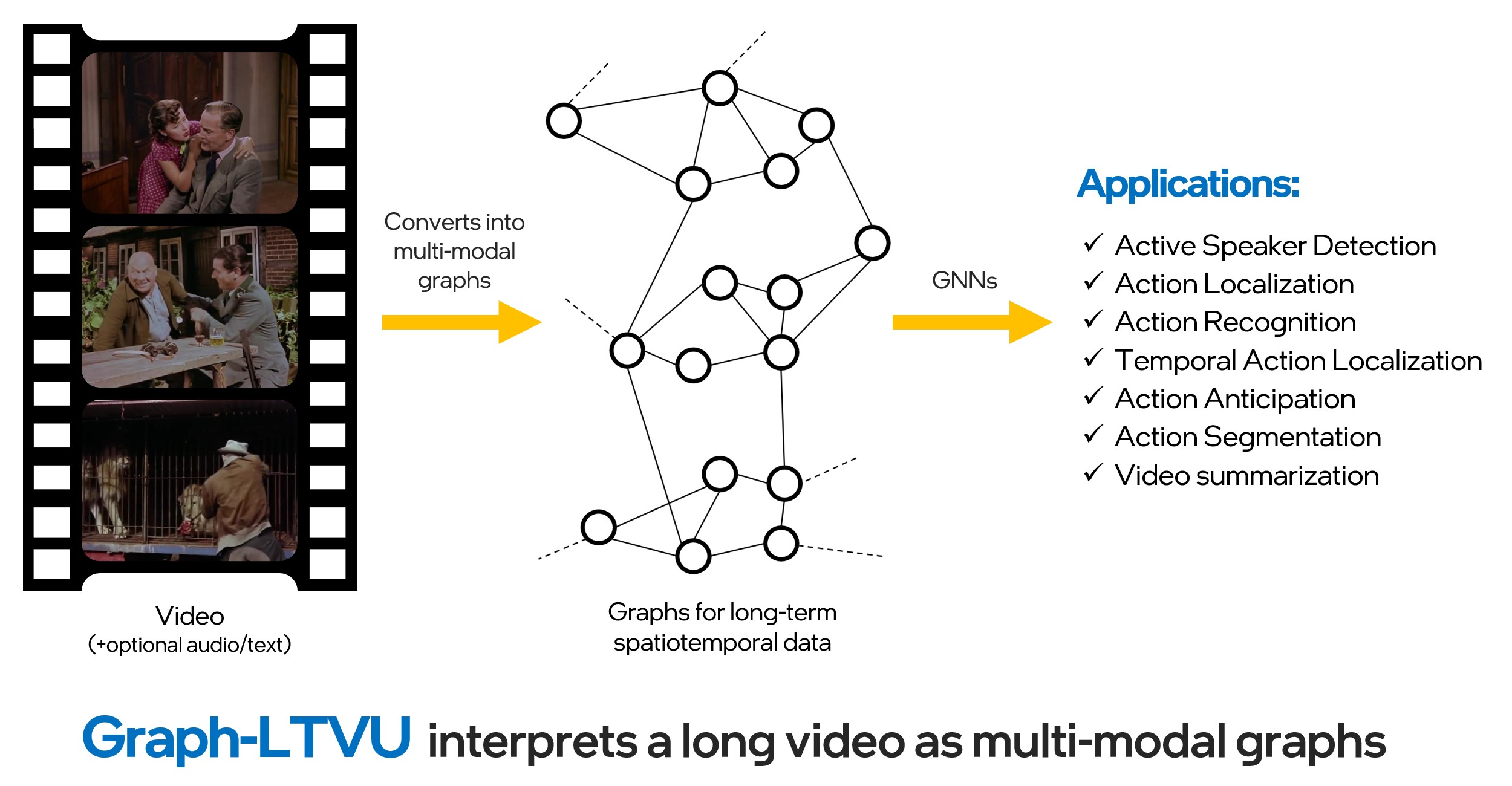
GraVi-T: A software library for long-term video understanding based on spatio-temporal graphs
Intel Labs has recently released GraVi-T . GraVi-T is an open-sourced toolbox for long-term video understanding based on spatio-temporal graph-based representations. This library is based on PyTorch and PyTorchGeometric. It is designed to serve as a spatial-temporal graph learning framework for multiple video understanding tasks. In the current version, it supports training and evaluating one of the state-of-the-art models, SPELL, for the tasks of active speaker detection (ASD) and action detection (AD) on Ava Active Speaker and AVA action datasets respectively.
In the near future, we will release more advanced graph-based approaches for other tasks such as heterogenous graph-based approach for the Ego4D audio-visual diarization challenge, action segementation. Stay tuned for incoming features such as Online SPELL. Till then, go to our GraVi-T github and run inference only or train your own models for ASD or AD. If you are interested to know more about the motativation, there goes the associated blog .